Mobile Legends: Bang Bang Professional League INDONESIA SEASON 10.
What is Mobile Legends?
Mobile Legends Bang Bang or knnown as MLBB is a popular mobile game MOBA RPG with a huge fanbases, Mobile legends: Bang Bang is huge in Indonesia and philippines. In fact it is so huge that the professional players playing in the MPL Indonesia have a six figure annual salary.
Why Mobile Legends?
The reality is just I'm just bored lol. Here in Indonesia Mobile Legends is so popular, almost all kids played it in here, even i frequently played it because I'm bored. So instead of just playing the game i want to test my skill to analyze the game. As the analysis is so important to the core game. also I'm inspired from Analyzing Former vs Current BoomID Carry Players: A Data-Driven Approach (solehudindt.pythonanywhere.com)
The Dataset
The dataset that i’m using is from Kaggle MPL ID Season 10 (kaggle.com). If im not wrong the dataset is from https://liquipedia.net/ but i cant found the API to use the latest dataset.
The Dataset contains all the information about the heroes used in MPL ID Season 10.
There were a total of 172 games played in MPL ID Season 10
Total_games = 172
- Hero: Name of the Hero.
- Hero_picked: Total number of times the hero was picked.
- T_wins: Total number of matches won with that hero.
- T_lose: Total number of matches lost with that hero.
- Twinrate: (Twins / Total_games )
- Tpickpercentage: (Heropicked / Total_games)
- Bs_picked: Number of times the hero picked by blue side.
- Bs_won: Number of times the blue side won with the hero.
- Bs_lost: Number of times the blue side lost with the hero.
- Bswinrate: (Bswon / Bs_picked)
- Rs_picked: Number of times the hero picked by Red side.
- Rs_won: Number of times the Red side won with the hero.
- Rs_lost: Number of times the Red side lost with the hero.
- Rswinrate: (Rswon / Rs_picked)
- Hero_banned: Number of times the hero was banned.
- Banpercentage: (Herobanned / Total_games)
- Pick&Ban: Number of times the hero was either picked or banned.
- Pick&Ban percentage: (Pick&Ban / Total_games)
before we going to analyze the data we have step by step process to go there. The first step is Data Wrangling.
Data wrangling is the process of gathering, selecting, and transforming data to answer an analytical question. Also known as data cleaning or ‘munging,’ legend has it that this wrangling costs analytics professionals as much as 80% of their time, leaving only 20% for exploration and modeling” (Elder Research).
The Data Wrangling process are include Gathering Data, Assessing Data, And Cleaning Data. The next step is Exploratory Data Analysis also known as EDA.
Exploratory Data Analysis (EDA) is an analysis approach that identifies general patterns in the data. These patterns include outliers and features of the data that might be unexpected. EDA is an important first step in any data analysis.
Essentially EDA is about exploring the data to make it into analysis or data visualization. You can find the full notebook in this link MPL Exploratory Data Analysis | Kaggle
Gathering Data
Gathering data in this context is just read the csv dataset and turn it into pandas data frame. Lets look general overview of the dataset

Assessing Data
Assessing data is also an important process before Exploratory Data Analysis. Assessing is just mean checking the data frame if there is an error in the dataset. An error in dataset generally means like a null data, a wrong data type etc.
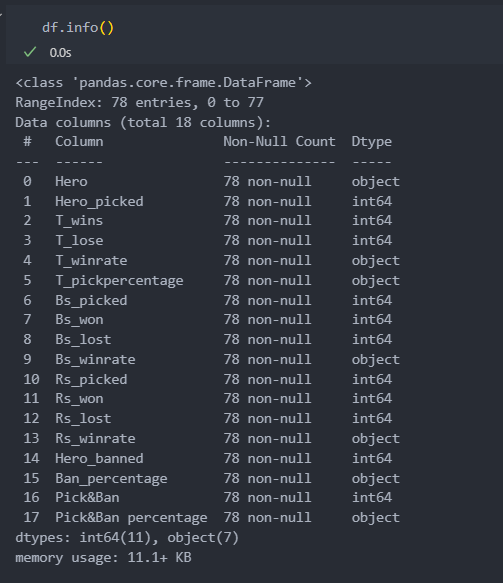
As you can see there is no null content in the dataframe so thats good. But there is a wrong datatype in the T_winrate, T_pickpercentage, etc. We actually want them to be numeric type so that we can do a comparison.
Cleaning Data
After the Assessing data we will clean the data. As what we said before we want the datatype of the percentage to be numeric.
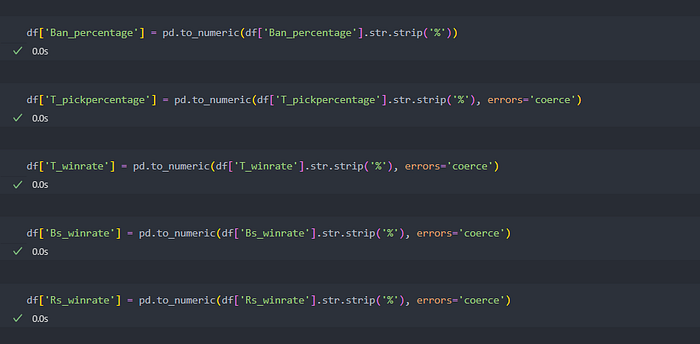
As you can see we delete the ‘%’ from the data and convert it to numeric.
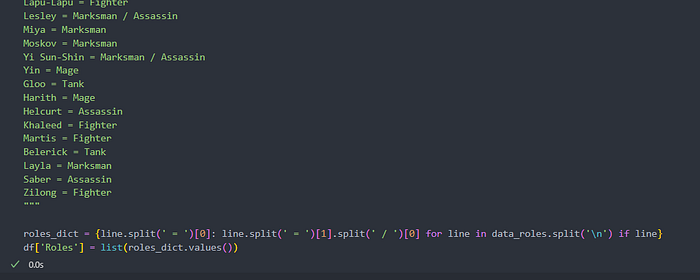
We also need to have a Heroes roles column, but because the dataset did not provide the roles column we need to add it ourself.
Exploratory Data Analysis
Now this is the fun part, lets just jump into it
General overview
Lets see the Top 10 Hero played in MPL ID Season 10
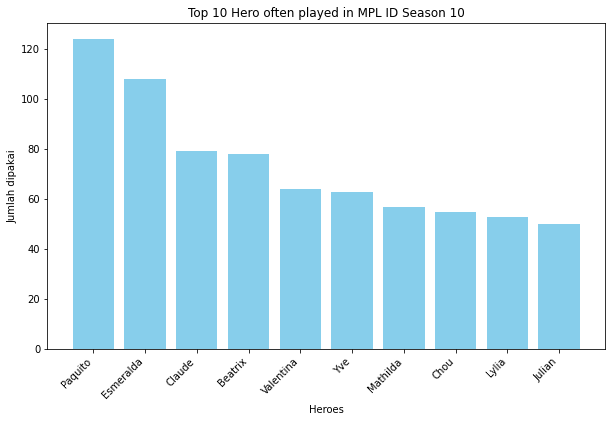
Paquito is the most played hero in the MPL Season 10. What about the Hero with the highest winrate tho.
As you can see that Miya, Estes, Lapu-lapu, Moskov, YSS, Edith, and Yin has a 100% Win rate in this MPL Season (Also notice we change to an interactive chart because the displayed data is pretty big).
Fanny, Wanwan and Faramis is the most banned heroes in this MPL Season
Team performance
Lets compare the Win rate of a heroes that picked by the Blue side and Red Side
As you can see the biggest difference is the hero Jawhead in red side has significantly more Win rate with the blue side
Correlation between Pick Rate and Win Rate
You can see the data distribution for the heroes pick rate and win rate. The highest win rate (100%) tends to have low pick rate
Are there heroes that were banned frequently but didn’t have a high Winrate?
The heroes that banned in more 50% of the games have a Win rate between 50% — 60% ish, while Fanny the most banned hero have such a low Win rate (35%)
What is the distribution of hero roles in the dataset?
The most picked hero roles are dominated with Fighter and Marksman
Compare the win rates of the top 5 most picked heroes with the win rates of the top 5 banned heroes.
The highest Win rate goes to 4th most picked heroes Beatrix and the rest of it goes to the top banned heroes (Except Fanny). Also coincidentally the 5th most picked and most banned is the same heroes Valentina.
Conclusion
so what's the conclusion then?
Were there any surprise picks that performed exceptionally well
Miya, Estes, Lapu-Lapu, Lesley, Moskov, Yi-Shun-Shin, Edith and Yin were all have low Pick rate and 100% Win rate.
Top Banned Heroes Have Mid Win Rate
Valentina, Akai, Faramis, Wanwan and Fanny were all banned in > 50% of the game but have mid (50% ish) win rate, except of course Fanny that have 35% of win rate
Correlation between Pick Rate and Win Rate
We see in the visualization that the highest (100%) win rate have a low pick rate and also the highest pick rate have 50% win rate which of course make sense.
The rest you can make the conclusion yourself.
People do not like to think. If one thinks, one must reach conclusions. Conclusions are not always pleasant.
- Helen Keller
Footnote
Python Big Data Exploration & Visualization: A Comprehensive Guide | Data And Beyond (medium.com)
How to Embed Interactive Plotly Visualizations on Medium Blogs | by Jennifer Banks | Medium